[Youtube] 넷플릭스 마이크로 서비스 가이드 3-1
유투브 출처 : 넷플릭스 마이크로 서비스 가이드 - 혼돈의 제왕
강의 순서
1. Introductions 00:00~5:38
2. Microservice Basics 05:39~13:18
3. Challenges & Solutions 13:19 ~ 43:33
1) Dependency 13:19 ~ 25: 02
2) Scale 25:03 ~ 33:33
3) Varience 33:34 ~ 43:33
4) Chagne 43:33~ 45:45
4. Organization & Architecture 46:46~53:13
3. Challenges & Solutions
지난 7년간 넷플릭스의 해법과 해법 철학으로 4가지 접근방법이 있다.
.
1) Dependency
2) Scale
3) Variance, 다양한 아키텍쳐의 수용
4) Change, 변화를 어떻게 처리할지
1) Dependecy
우선 의존성 (Dependency)에는 4가지 사례로 설명할 수 있다.
|
사례 1. Intra-Service requests 사례 2. Client librariesData 사례 3. Persistence 사례 4. Infrastructure |
사례1. Intra-Service requests
인트라 서비스 요청들, 이건 마이클 서비스 A가 마이크로 서비스 B를 호출하고 이런 내부 요청은 클라이언트 요청을 처리하기 위해 필요하다.서비스가 다른 서비스를 호출 할때 프로세스와 서버를 벗어나서 다른 서버의 프로세스까지 가는 것이 큰 모험이다. 네트워크의 지연시간, 혼잡성, 하드웨어 오류, 트랙픽으로 인한 라우팅 문제 또는 호출한 서비스가 정상적인 상태가 아닐 수도 있다. 예를 들면 잘못된 배포나 논리적 버그 같은 문제들... 적절한 규모로 확장되지 모했거나 요청에 대한 응답이 느려지거나, 타임 아웃이 발생하거나 에러가 발생하게 된다

굉장히 많이 발생하는 장애 시나리오 중의 하나는 이 시나리오에서 하나의 서비스에서 장애가 발생한다면 즉, 한개의 서비스 장애에 대해 잘못된 방어 구조를 가지고 있는 경우에 는 이 하나의 장애가 의존성이 있는 다른 서비스의 장애를 야기하는 연속 장애가 발생하고, 결과적으로 전체 서비스에 문제가 생긴다. 이런 문제는 문제가 발생한 지역을 살펴보아야한다. 이런 문제를 방지하기 위해서 넷플릭스는 Hystrix라는 도구를 만들었다.
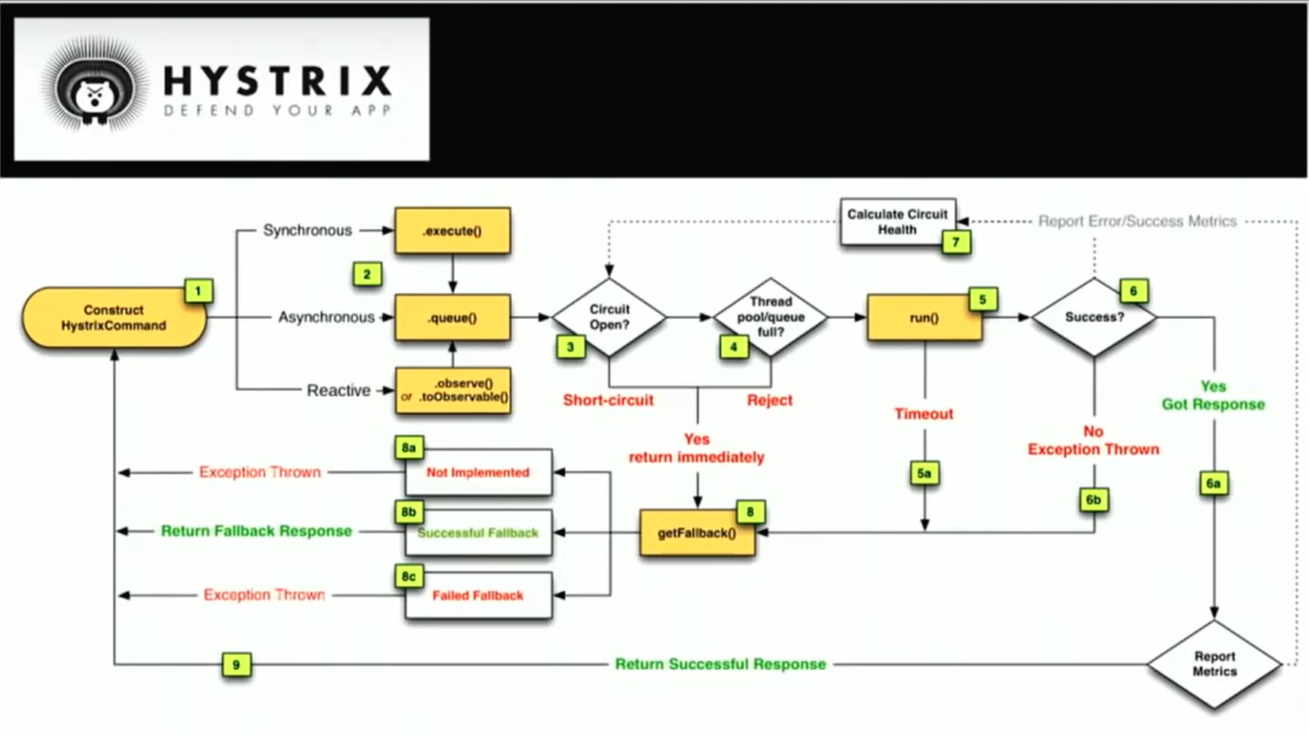
이 도구는 타임아웃이나 재시도 같은 동작을 구조적으로 다룰 수 있다. 그리고 fallback 이라고 불리는 컨셉을 가지고 있는데 이 건 만약 내가 서비스 B를 호출 할 수 없다면 사전에 지정된 static한 응답을 주는 등의 동작을 하는 것이다. 이건 고객이 에러를 보게 하는 대신, 서비스가 계속 동작하는 것처러 보이게 할 수 있다. 그리고 Hystrix가 제공하는 아주 큰 장점은 '고립된 스레드 풀'과 '서킷'에 대한 컨셉이다. 만약 서비스 B가 장애인 상황에서 계속 호출하는 것보다는, 호출을 중지하는게 더 좋은 방법일 것이다. 장애가 감지되면 지정된 fallback으로 응답하고, 서비스 B가 복구되길 기다린다. Hystrix는 오늘날 넷플릭스 안에서 매우 광범위하게 사용되고 있다.
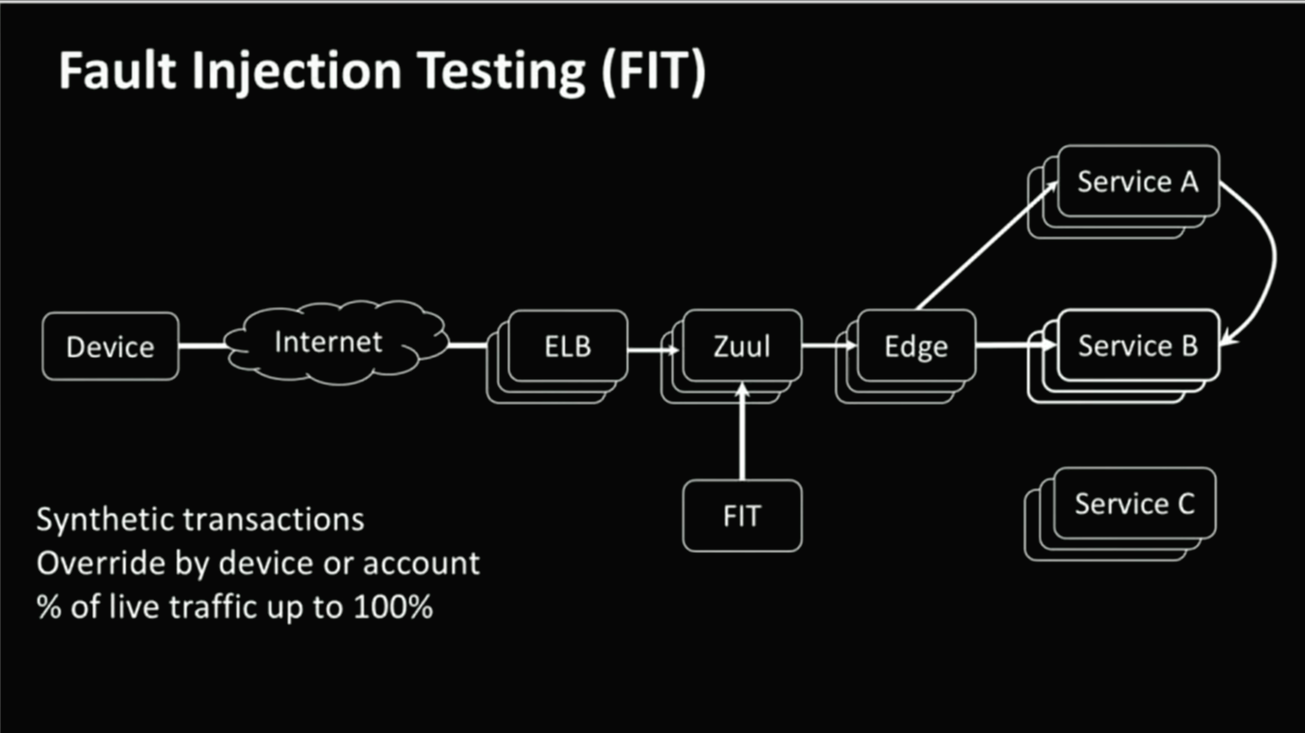
How do you know if it works?
마이크로 서비스들을 올바르게 설정한 것같고, Hystrix도 올바르게 설정을 완료 했다면 이런것 구조가 제대로 동작하는지 어떻게 알수 있을까? 이것은 예방접종의 방식과 비슷하다. 실패를 프로덕션에 주입하는 방법을 통해 장애에 대한 내성을 가질 수 있다. 이 '실패 주입'을 위해 넷플릭스는 FIT를 만들었다.(장애 주입 테스트 프레임 워크) FIT는 장치나 어카운트에서 발생된 요청을 실패를 유발하는 설정과 오버라이드해서 만들어진 '합성 트랜젝션'을 프로덕션에 주입할 수 있다. 그리고 FIT로 서비스에 유입되는 합성 트랜잭션: 라이브 트랙픽의 비율을 조정할 수 있다. 모든게 정상 동작한다고 생각되면, 라이브 트랙픽의 비율을 늘려서 실제 부하 상태에서도 정상동작 하는지 확인 한다. FIT에서는 어떤 형태의 테스트건 모두 수행할 수 있어야 한다. 직접 호출하건 직접 호출하지 않건간에 테스트하려는 합성 트랜젝션을 올바르게 설정하면 프로덕션에서의 서비스 다운없이 서비스에 발생할 문제를 시뮬레이션할 수 있다.

위의 그림은 포인트-포인트 연결을 잘보여준다. 100개의 마이크로 서비스가 동작한다고 생각해보라. 그리고 이서비스들은 하나 또는 여러개의 다른 서비스에 의존성을 가지고 있다. 여기서 매우 큰 도전이 발생하는데 서비스의 테스트와 범윌르 어떻게 제한해야 수백개의 서비스가 서로 통신하는 걸 전부 시뮬레이션하지 않고 테스트를 진행할 수 있을까 이다. 이런 테스트는 가용성 측면에서 매우 중요한 문제이다. 여러분의 서비스가 단 10개의 서비스로 이루어졌다고 하자. 그리고 각각의 서비스는 99.99%의 가용성으로 동작하는데, 이건 1년에 53분의 다운만 허용하는 수치이다. 가용성 관련 숫자로는 대단한것 같지만 일년간의 수치를 모두 다 합쳐보면 전체 서비스는 99.9의 가용성을 가지게 된다. 이건 1년에 8-9시간의 장애에 해당하며 53분과는 큰 차이이다. 이런 테스트 목적을 달성하기 위해 넷플릭스는 먼저 '치명적인 마이크로 서비스들'을 정의했다. 이는 테스트의 대상이되는 기능의 동작을 위해 필수적으로 필요한 서비스들을 가려낸다. 이를테면 고객이 어플리케이션을 구동하고 어떤 영화를 보아야 할지 브라우징을 하고 영화 리스트에서 가장 마음에 드는 영화를 선택하고 플레이버튼을 누르면 재생이 되어야 하는 것이다. 이런 일련의 과정에 치명적인 의존성을 가지고 있는 서비스들을 분류하여 그룹화 한다. FIT 레시피를 만들 때, 이 그룹 말고 나머지는 모두 블랙리스트로 배제한다. 이렇게 만들어진 레시피로 원하는 대상 기능의 서비스들만을 프로덕션에서 테스트 한다. 따라서 의존성이 있는 서비스들이 동작하지 않는 상태도 만들어 장애 상황에서 원하는대로 동작하는지 확인한다. 이 방법은 모든 포인트 - 포인트 연동을 확인하지 않아도 되는 단순함을 제공하며 넷플릭스 서비스에 존재하는 치명적인 에러를 찾아내는데 매우 큰 도움을 주었다.
사례 2. Client libraries
이제 클라이언트 라이브러리에 대해 이야기해보자. 처음 클라우드로 서비스를 이전하면서, 클라이언트 라이브러리에 대한 뜨거운 논쟁이 있었다. 야후에서 일했던 뛰어난 분들이 넷플릭스로 많이 왔는데 이분들은 '베어 본 REST'라 불리는 모델의 강력한 지지자들이 많았다. 어떠한 클라이언트 라이브러리도 사용하지 않고 모든 요청을 베어-본으로 처리하는 것이다. 동시에 클라이언트 라이브러리를 만들어야 하나는 주장 역시 강력했다. 만약 공통 로직과 공통 접근 패턴을 가지고 있는 상태에서 내 서비스에 20-30개의 서비스 의존성이 있는 상태라면 모든 팀들이 내 서비스 접근을 위해 동일하거나 유사한 코드를 매번 작성하도록 하는 것이 맞는지 아니면 이런것들을 공통 비즈니스 모델로 통합하고 공통 접근 패턴을 사용하는 것이 좋은지에 대한 격렬한 논쟁의 내용이었다.
이 라이브러리 논쟁에서 어려운 점은 다시 새로운 형태의 모놀리틱 형태가 발생할 수 있다는 것이다. 여기 수백개의 서비스의 연결을 처리해야하는 API 게이트웨이가 있다. 결과적으로 게이트웨이 프로세스안에 엄청나게 많은 라이브러리가 동작하게 된다. 이건 2000년대 초반까지 사용했던 모놀리틱처럼 거대한 코드베이스가 되어 버렸다. 이런 모습은 기생충 감염 상태와 매우 유사하다. 이건 무슨 고질라 같은 거대 괴물이 도쿄를 파괴하는 그런 것이 아니라 장기에 서식하면서 혈관에 딱 붙어 드라큐라 같이 피를 먹고 사는 것이다. 이와 같이 아무 지식 없이 사용하는 클라이언트 라이브러리는 여러분의 서비스를 비슷한 방식으로 약하게 만들 수 있다. 여러분이 예상했던 것 이상의 heap을 사용하거나 애플리케이션 안에서 논리적 오류를 일으킬 수도 있으며 다른 의존성이 있는 라이브러리와 충돌하거나, 빌드가 깨지거나 하는 등의 문제이다. 이게 실제로 일어났던 현상이다 API 팀에서 먼저 생겼는데, 바로 이부분이 수많은 팀에서 만든 수많은 라이브러리르 사용해야 했기 때문이다. 여기에 확실한 해답은 없다. 수많은 논의들이 있지만 아직까지 어떤 결론이 나지는 않았다.

지금까지 나온 방법으로는, 이런 라이브러리를 더 간단한 규모로 만드는 것이다. 모든 요청을 성능상의 이유로 베어-본 REST 모델로 만들 필요는 없지만, 로직의 규모나 heap 사용등을 제한할 필요는 있다. 아직 논의중인 문제라 결론이 난 것은 아니지만 이걸 설명드린 이유는, 어떤 상황에 어떤 것을 선택해야 하는지에 대한 이해를 공유하기 위함이다.
사례 3. Persistence
제 생각엔 넷플릭스가 초반부터 잘 구성한 부분이 바로 데이터 저장구간이다. 따라서 어떻게 잘못 고쳤는지 같은 전쟁사는 없다. 올바른 구현을 어떻게 했는지를 알아보자. 시작은 CAP 이론을 어떻게 올바르게 구현할 것인가 였다. CAP이론은 네트워가 분리된 환경에서는 가용성과 일관성 중 반드시 하나를 선택해야 한다는 것이다. 아래 그림을 보면 네트워크 A에서 동작하는 서비스가 있다 이서비스는 동일한 데이터를 여러개의 데이터 베이스에 각각 저장하려고 하는데 이 데이터베이스들은 서로 다른 네트워크에 존재한다.

AWS 기준으로는 3개의 다른 AZ이다. 기초적인 질문은 만약 한개 이상의 데이터 베이스 접근이 안되면 어떻게 할 것인가 이다. 실패를 그대로 받아들이고, 에러를 리턴할 것인지 일단 되는곳에 먼저 저장하고, 나중에 정상화 되면 복제할 것인지이다. 넷플릭스는 후자를 선택했다. 바로 '최종 일관성'을 추구하는 형태였다. (Eventual Consistency). 데이터를 저장하고 난 직후에 즉시 읽기를 수행하지 않는 방식이다.

카산드라는 이런 형태의 작업을 정말 훌륭하게 처리한다. 굉장히 유연하다. 클라이언트가 하나인 노트에만 쓰기를 수행해도, 이 데이터를 모든 노드에 알아서 복제한다. 그리고 여기엔 '정족수' 컨셉이 있는데 지정한 숫자 이상의 노드에서 변경에 대한 확인이 있어야 실제 데이터에 대한 변경이 적용되는 방법이다. 제가 데이터를 변경 됬다고 가정하는 대신 말이다. 만약 매우 높은 가용성을 목적으로 내구성을 위험을 감수하나면 이 정족수는 1대의 노드로 적용할 수 있으며 반대로 내구성을 높이기 위해서라면 모드 노드에 대한 복제가 되어야 변경된 것으로 간주할 수도 있다.
사례 4. Infrastructure
이제 오늘의 전체 주제인 인프라에 대한 이야기로 넘어가겠다. 언제 어떤 순간에서든 AWS건 구글이건 여러분이 직접 구성한 인프라건 간에 장애는 반드시 발생합니다. 여거시의 포인트는 아마존이 서비스를 못한다는 것이 아니다. 사실은 매우 훌륭하다. 모든 건 고장날 수 있다는 것을 의미한다. 2012년 크리스마스 이브에 발생한 장애에 대해 살펴보자면 ELB에 대한 제어 부분이 다운 되었는데 마치 제 가지 계란을 모두 한 바구니에 넣은 것처럼 넷플릭스의 모든 리소스가 us-east-1에 있었다. us-east-1에 장애가 발생하자 마자 해당 리전이 문제가 된 후 대안이 없었다. 그래서 넷플릭스는 3개의 AWS 리전을 바탕으로 멀티 리전 전략을 구상했다. 이제는 어떤 리전이 완전히 동작하지 않는 경우에도 서비스에는 전혀 문제가 없다.