이번 주제는 TensorFlow Speech Recognition Challenge 이다.
간단한 단어들을 녹음한 오디오 파일을 듣고 어떤 단어인지 예측하는 것이 목표이다.
음성 인식 분야 머신러닝이 생소 할 수 있지만,
DavidS 님의 Speech representation and data exploration 를 참고하여 음성 데이터를 어떻게 접근하면 되는지를 목표로 필사를 진행하였다.
이 커널에서는 예측하여 결과를 내는 것이 아닌 음성 파일 데이터를 EDA로 분석하는 수준을 목표로 한다.
참고 : 아래 jupyter notebook 파일을 html로 바로 복붙했더니 오디오 파일 소리는 확인할 수 없다. 오디오 파일 소리는 github 소스코드 바로가기 나 kaggle 커널로!
이제 차근차근 따라가 봅시다.
목록
TensorFlow Speech Recognition Challenge (1)
1.1. Wave and spectrogram
1.2. MFCC
1.3. Sprectrogram in 3d
1.4. Silence removal
1.5. Resampling - dimensionality reductions
1.6. Features extraction steps0
TensorFlow Speech Recognition Challenge (2)
2.1. Number of files
2.2. Deeper into recordings
2.3. Recordings length
2.4. Mean spectrograms and fft
2.5. Frequency components across the words
2.7. Anomaly detection
TensorFlow Speech Recognition Challenge
2. Dataset investigation
2.1. Number of files
dirs = [f for f in os.listdir(train_audio_path) if isdir(join(train_audio_path, f))]
dirs.sort()
print('Number of labels: ' + str(len(dirs)))
dirs
# 계산
number_of_recordings = []
for direct in dirs:
waves = [ f for f in os.listdir(join(train_audio_path, direct))
if f.endswith('.wav')]
number_of_recordings.append(len(waves))
# plot
data = [go.Histogram(x=dirs, y = number_of_recordings)]
trace = go.Bar(
x=dirs,
y=number_of_recordings,
marker=dict(color = number_of_recordings, colorscale='ylorrd',
showscale=True),
)
layout = go.Layout(
title='Number of recordings in given label',
xaxis=dict(title='Words'),
yaxis=dict(title='Number of recordings')
)
py.iplot(go.Figure(data=[trace], layout=layout))
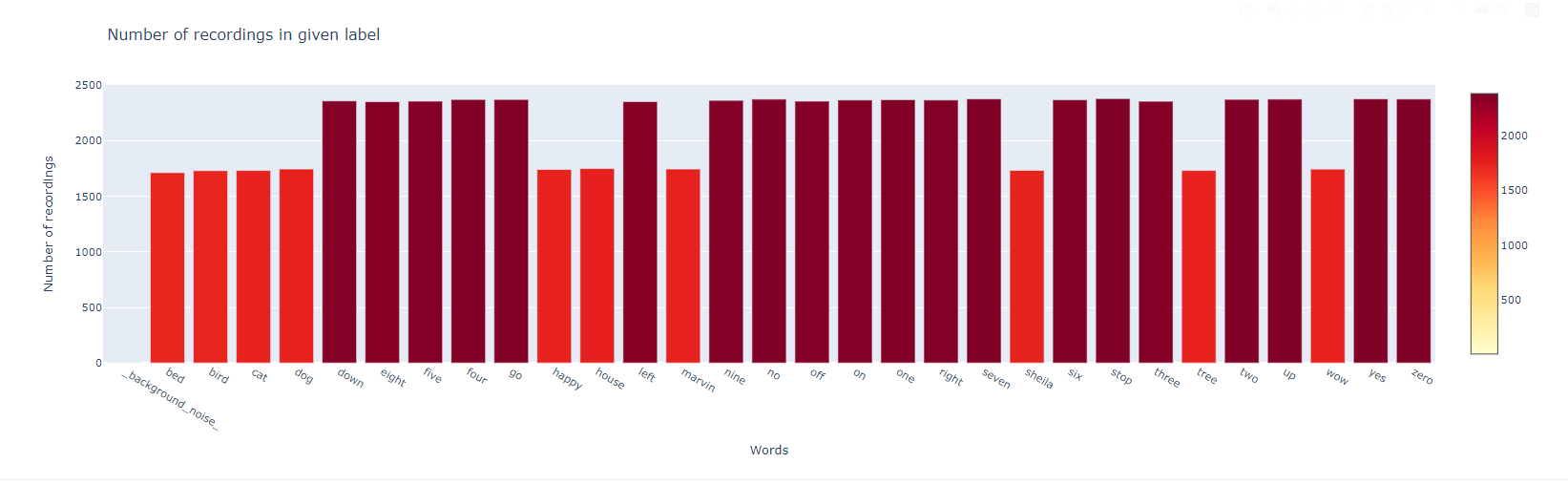
데이터 셋은 background_noise 를 제외하고 균형있다. 하지만 다른것도 있다.
2.2. Deeper into recordings
아주 중요한 사실이 있다. 녹음은 매우 다른 출처에서 나온다. 내가 알기로는, 그들 중 일부는 이동형 GSM 채널에서 올 수 있다.
그럼에도 불구하고, 한명의 발화자가 test 와 train data으로 분리 되지 않는 것이 매우 중요하다. 이 두 가지 시험 유형을 보고 들어 보자.
filenames = ['on/004ae714_nohash_0.wav', 'on/0137b3f4_nohash_0.wav']
for filename in filenames:
sample_rate, samples = wavfile.read(str(train_audio_path) +
filename)
xf, vals = custom_fft(samples, sample_rate)
plt.figure(figsize=(12,4))
plt.title('FFT of speaker' + filename[4:11])
plt.plot(xf, vals)
plt.xlabel('Frequency')
plt.grid()
plt.show()


들어 보는 것이 더 정확할 수 있다.
print('Speaker ' + filenames[0][4:11])
ipd.Audio(join(train_audio_path, filenames[0]))
print('Speaker ' + filenames[1][4:11])
ipd.Audio(join(train_audio_path, filenames[1]))
아래 녹음에는 이상한 침묵이 있다. 아마 압축하는 과정에서 생겼을수도 있다.
filename = '/yes/01bb6a2a_nohash_1.wav'
sample_rate, samples = wavfile.read(str(train_audio_path) + filename)
ipd.Audio(samples, rate = sample_rate)
freqs, times, spectrogram = log_specgram(samples, sample_rate)
plt.figure(figsize=(10,7))
plt.title('Spectrogram of ' + filename)
plt.ylabel('Freqs')
plt.xlabel('Time')
plt.imshow(spectrogram.T, aspect='auto', origin='lower',
extent=[times.min(), times.max(), freqs.min(), freqs.max()])
plt.yticks(freqs[::16])
plt.xticks(times[::16])
plt.show()

즉, 우리는 매우 특정한 음향 환경에서 과도하게 적응하는 것을 막아야 한다.
2.3. Recordings length
모든 파일이 1초동안 구성되어 있는지 확인해보자.
num_of_shorter= 0
for direct in dirs:
waves= [f for f in os.listdir(join(train_audio_path, direct))
if f.endswith('.wav')]
for wav in waves:
sample_rate, samples = wavfile.read(train_audio_path +
direct + '/' + wav)
# print('확인 : ',samples.shape[0], sample_rate)
if samples.shape[0] < sample_rate:
num_of_shorter +=1
print('Number of recordings shorter than 1 second: '+ str(num_of_shorter))
놀랍게도 많은 데이터 들이 0에 가까운 파일 시간을 가지고 있다.
2.4. Mean spectrograms and fft
모든 단어의 mean FFT plot을 보자.
to_keep = 'yes no up down left right on off stop go'.split()
dirs = [d for d in dirs if d in to_keep]
print(dirs)
for direct in dirs:
vals_all = []
spec_all = []
waves = [f for f in os.listdir(join(train_audio_path, direct))
if f.endswith('.wav')]
for wav in waves:
sample_rate, samples = wavfile.read(train_audio_path + direct + '/'+wav)
if samples.shape[0] != 16000:
continue
xf, vals = custom_fft(samples, 16000)
vals_all.append(vals)
freqs, times, spec = log_specgram(samples, 16000)
spec_all.append(spec)
plt.figure(figsize=(14,4))
plt.subplot(121)
plt.title('Mean fft of ' + direct)
plt.plot(np.mean(np.array(vals_all), axis=0))
plt.grid()
plt.subplot(122)
plt.title('Mean spectrogram of ' + direct)
plt.imshow(np.mean(np.array(spec_all), axis=0).T, aspect='auto',
origin='lower', extent=[times.min(), times.max(),
freqs.min(), freqs.max()])
plt.yticks(freqs[::16])
plt.xticks(times[::16])
plt.show()










2.5. Frequency components across the words
def violinplot_frequency(dirs, freq_ind):
spec_all = []
ind=0
for direct in dirs:
spec_all.append([])
waves = [f for f in os.listdir(join(train_audio_path, direct))
if f.endswith('.wav')]
for wav in waves[:100]:
sample_rate, samples = wavfile.read(
train_audio_path + direct + '/' + wav)
freqs, times, spec = log_specgram(samples, sample_rate)
spec_all[ind].extend(spec[:, freq_ind])
ind +=1
minimun = min([len(spec) for spec in spec_all])
spec_all = np.array([spec[:minimun] for spec in spec_all])
plt.figure(figsize=(13,7))
plt.title('Frequency' + str(freqs[freq_ind]) + ' Hz')
plt.ylabel('Amount of frequency in a word')
plt.xlabel('Words')
sns.violinplot(data=pd.DataFrame(spec_all.T, columns=dirs))
plt.show()
violinplot_frequency(dirs, 20)

violinplot_frequency(dirs, 50)

violinplot_frequency(dirs, 120)

2.7. Anomaly detection
우리는 눈에 띄는 녹취록이 있는지 확인해야한다. 데이터 집합의 차원을 낮추고 이상 징후가 있는지 대화식으로 확인할 수 있다. 데이터 차원을 감소하기 위해 PCA를 사용해보자.
fft_all = []
names = []
for direct in dirs:
waves = [f for f in os.listdir(join(train_audio_path, direct)) if f.endswith('.wav')]
for wav in waves:
sample_rate, samples = wavfile.read(train_audio_path + direct + '/' + wav)
if samples.shape[0] != sample_rate:
samples = np.append(samples, np.zeros((sample_rate - samples.shape[0], )))
x, val = custom_fft(samples, sample_rate)
fft_all.append(val)
names.append(direct + '/' + wav)
fft_all = np.array(fft_all)
# Normalization
fft_all = (fft_all - np.mean(fft_all, axis=0)) / np.std(fft_all, axis=0)
# Dim reduction : 차원 축소
pca = PCA(n_components=3)
fft_all = pca.fit_transform(fft_all)
# 3d 차트로보기
def interactive_3d_plot(data, names):
scatt = go.Scatter3d(x=data[:, 0], y=data[:, 1], z=data[:, 2], mode='markers', text=names)
data = go.Data([scatt])
layout = go.Layout(title="Anomaly detection")
figure = go.Figure(data=data, layout=layout)
py.iplot(figure)
interactive_3d_plot(fft_all, names)

`위의 그림에서 떨어져 있는 이상치를 들어보자. 그 중에서도 yes/e4b02540_nohash_0.wav, go/0487ba9b_nohash_0.wav 의 포인트들은 중앙으로부터 많이 떨어져있다.
print('Recording go/0487ba9b_nohash_0.wav')
ipd.Audio(join(train_audio_path,'go/0487ba9b_nohash_0.wav'))
print('Recording yes/e4b02540_nohash_0.wav')
ipd.Audio(join(train_audio_path, 'yes/e4b02540_nohash_0.wav'))
위의 소리는 지지직 거리거나 잡음이 많이 껴 있음을 확인할 수 있다.
만약 개별 단어의 이상치가 궁금하다면, seven 폴더에서 찾아볼 수 있다.
print('Recording seven/e4b02540_nohash_0.wav')
ipd.Audio(join(train_audio_path, 'seven/e4b02540_nohash_0.wav'))
분명히 중요한게 아니지만, 이방법을 사용하면 약간의 왜곡을 발견할 수 있다.
'Competition > Kaggle' 카테고리의 다른 글
| [kaggle][필사] Zillow Prize: Zillow’s Home Value Prediction (1) (0) | 2020.10.18 |
|---|---|
| [kaggle][필사] TensorFlow Speech Recognition Challenge (1) (0) | 2020.10.08 |
| [kaggle][필사] New York City Taxi Duration (3) (0) | 2020.10.05 |