비지도 학습을 사용해 데이터를 변환하는 이유는 여러가지가 있다.
가장 일반적인 동기는 시각화, 데이터 압축, 지도학습을 위한 처리를 위해 정보가 더 잘드러나는 표현을 찾기 위해서 이다.
이런 용도로 가장 간단하고 흔히 사용하는 알고리즘인 주성분 분석(PCA)이 있는데,
그 외에 2차원 산점도를 이용해 시각화 용도로 많이 사용하는 t-SNE(t-distributed stochasitc neighbor embedding) 알고리즘을 살펴 보자.
데이터를 산점도로 시각화할 수 있다는 이점을 가진 PCA는 데이터 변환에 가장 먼저 시도해볼 수 있는 방법이지만,
알고리즘의 회전하고 방향을 제거하는 유용성은 떨어진다.
이를 해결하기 위해 매니 폴드라는 알고리즘이라고 하는 시각화 알고리즘들은 훨씬 복잡한 매핑을 만들어 더 나은 시각화를 제공한다. 이중에 하나가 t-SNE 이다.
특징
- 매니폴드 알고리즘 중 하나
- 매니폴드 학습은 탐색적 데이터 분석에 유용, 지도학습에는 거의 사용하지 않음.
- t-SNE의 아이디어는 데이터 포인트를 2차원에 무작위로 표현한 후 원본 특성 공간에서 가까운 포인트는 가깝게, 멀리떨어진 포이트는 멀어지게 만드는 것.
- 이웃 데이터 포인트에 대한 정보를 보전하려고함.
예제
- scikit-learn에 있는 손글씨 데이터셋
- 각 포인트는 0~9 사이의 손글씨 숫자를 표현한 8*8 크기의 흑백 이미지
- 아래는 숫자 데이터셋의 샘플 이미지이다.
digits = load_digits()
fig, axes = plt.subplots(2,5,figsize=(10,5),
subplot_kw = {'xticks':(), 'yticks':()})
for ax, imgs in zip(axes.ravel(), digits.images):
ax.imshow(imgs)
- PCA를 사용해 데이터를 2차원으로 축소한 시각화
from sklearn.decomposition import PCA
# 2차원으로 축소
pca = PCA(n_components=2)
pca.fit(digits.data)
# 처음 두 개의 주성분으로 숫자 데이터를 변환
digits_pca = pca.transform(digits.data)
colors = ["#476A2A", "#7851B8", "#BD3430", "#4A2D4E", "#875525",
"#A83683", "#4E655E", "#853541", "#3A3120","#535D8E"]
plt.figure(figsize=(10,10))
plt.xlim(digits_pca[:, 0].min(), digits_pca[:, 0].max())
plt.ylim(digits_pca[:, 1].min(), digits_pca[:, 1].max())
for i in range(len(digits.data)):
plt.text(digits_pca[i, 0], digits_pca[i,1], str(digits.target[i]),
color = colors[digits.target[i]] ,fontdict={'weight': 'bold', 'size':9} )
## fontdict={'weight': 'bold', 'size':9}
plt.xlabel("첫 번째 주성분")
plt.ylabel("두 번째 주성분")

- 위의 산점도를 보면 0,6,4는 두 개의 주 성분만으로 비교적 잘분리된 것 같다.
- 하지만 아직 중첩된 부분이 있고, 다른 숫자들은 대부분 많은 부분이 겹쳐 있다.
이제 t-SNE를 적용한 결과를 보자.
t-SNE는 새 데이터를 변환하는 기능을 제공하지 않으므로 TSNE 모델에는 transform 메서드가 없다.
대신 모델을 만들자마자 데이터를 변환해주는 fit_transform 메서드를 사용할 수 있다.
from sklearn.manifold import TSNE
tsne = TSNE(random_state = 42)
# TSNE에는 transform 메서드가 없으므로 대신 fit_transform을 사용한다.
digits_tsne = tsne.fit_transform(digits.data)
plt.figure(figsize=(10,10))
plt.xlim(digits_tsne[:,0].min(), digits_tsne[:,0].max()+1)
plt.ylim(digits_tsne[:,1].min(), digits_tsne[:,1].max()+1)
for i in range(len(digits.data)):
plt.text(digits_tsne[i,0], digits_tsne[i,1], str(digits.target[i]),
color = colors[digits.target[i]],
fontdict = {'weight':'bold','size':9})
plt.xlabel("t-SNE 특성 0")
plt.ylabel("t-SNE 특성 1")
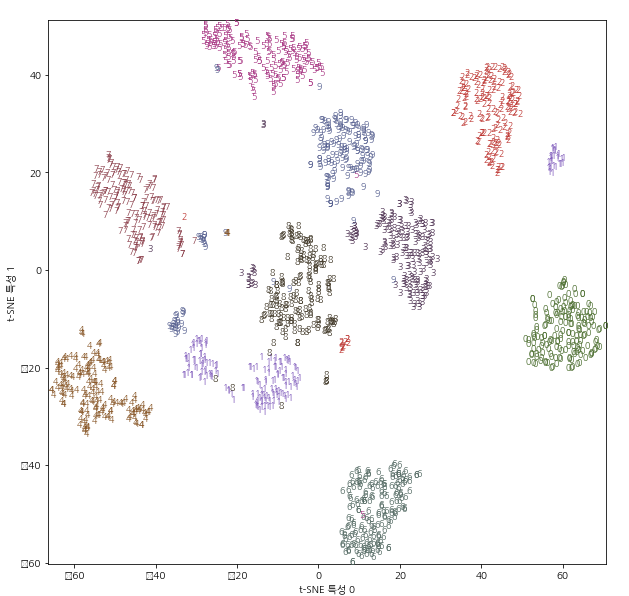
t-SNE 결과 모든 클래스가 확실히 잘 구분되어 있다.
1과 9는 조금 나뉘었지만 대부분의 숫자는 하나의 그룹으로 모여있다.
'Study > Data Analysis' 카테고리의 다른 글
| [양식] 논문 선행연구 엑셀 정리 (3) | 2021.02.05 |
|---|---|
| [python] 공공자전거 데이터 분석(4) - pivot data 생성 (0) | 2020.04.28 |
| [python] 공공자전거 데이터 분석(3) - 상관관계 분석 (0) | 2020.04.27 |