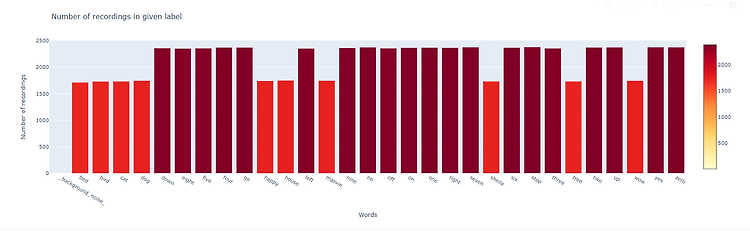
이번 주제는 TensorFlow Speech Recognition Challenge 이다. 간단한 단어들을 녹음한 오디오 파일을 듣고 어떤 단어인지 예측하는 것이 목표이다. 음성 인식 분야 머신러닝이 생소 할 수 있지만, DavidS 님의 Speech representation and data exploration 를 참고하여 음성 데이터를 어떻게 접근하면 되는지를 목표로 필사를 진행하였다. 이 커널에서는 예측하여 결과를 내는 것이 아닌 음성 파일 데이터를 EDA로 분석하는 수준을 목표로 한다.참고 : 아래 jupyter notebook 파일을 html로 바로 복붙했더니 오디오 파일 소리는 확인할 수 없다. 오디오 파일 소리는 github 소스코드 바로가기 나 kaggle 커널로! 이제 차근차근..